使用MySQL已经有一段时间了,对学习的知识来个总结吧。尽管知识有限还是向总结一下,好了,不多说了,一下是正文。
(个人比较喜欢在控制台操作,以下都是在控制台操作的)
MySQL安装的时候,一般都会连文档一并安装到本地的,因此要好好运用这个文档吧。
win+r cmd进入控制台。
控制台: \h 可以查看所有的命令。
![]()
![]()
![]()
a.查看帮助主题(相当于目录)
控制台输入: ? contents
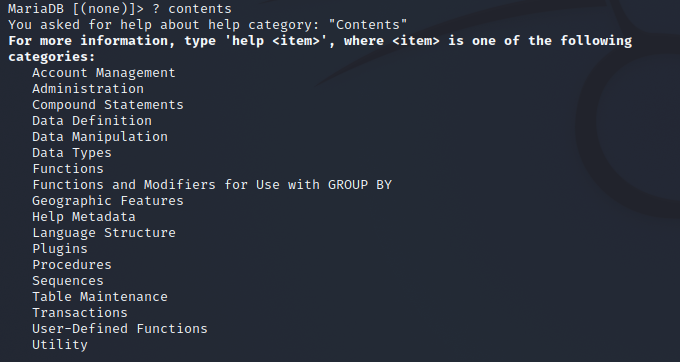
以上列表所有的分类。可以通过 ? categories名 查看每个categories的详细信息。
例如要查看 functions下面的文档内容,控制台输入: ? functions (大小写都是可以的)
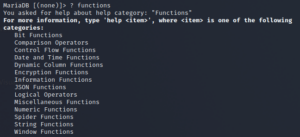
要查看MySQL的相关文档,都是可以通过「? + 关键字」来查看的。
b. show的使用
①查看DB中所有的数据库: show databases;
②选择一个数据库使用: use databaseName
③查看使用数据库中的所有的表: show tables;
④查看一个表创建的详细内容,外键以及创建时的引擎: show create table tabName;
⑤查看一个表的所有字段: show columns from tabName from databaseName 或者使用 show columns from databaseName.tabName;
⑥查看使用数据库中每个表的信息: show table status \G;
⑦查看一个表的索引: show index from tabName \G;
⑧查看可用的存储引擎: show engines \G;
⑨查看最后一个执行语句产生的错误消息: show errors;
⑩查看最后一个执行语句产生的错误,警告和通知: show warnings;
十一查看一个用户的权限: show grants for root@localhost;
十二查看系统变量的名称和值: show variables;
十三查看系统特定资源信息: show status;
十四服务器所支持的不同权限: show privileges;
十五查看系统中正在运行的所有程序: show processlist;
十六查看所有存储过程: show procedure status;
十七查看所有存储过程: show function status;
十八查看表中所有列的字符集 : show full columns from tb_name;
十九查看mysql所支持的字符集 : show charset;
c. 查看MySQL的版本: select version();
d. 查看db的当前的使用者: select user();
e. tee的使用
记录控制台上的所有操作: tee d:\文件名.log
或者 \T d:\文件名.log (\T T一定要大写) (\h 可以查看)
关闭tee 功能: notee 或者 \t
f. 修改root用户的密码: ①UPDATE mysql.user SET password=PASSWORD(‘新密码’) WHERE User=’root’;FLUSH PRIVILEGES;②首先在DOS下进入目录mysql\bin,再运行一下代码: mysqladmin -u用户名 -p旧密码 password新密码
g. 用户权限
1.–创建用户并授权,格式:grant 权限 on 数据库.* to 用户名@登录主机 identified by ‘密码’;
grant select on 数据库名.* to 用户名@登录主机 identified by ‘密码’;(只有select权限)
2. 授权test用户拥有所有数据库的某些权限: @”%” 表示对所有非本地主机授权,不包括localhost。
grant select,delete,update,create,drop on *.* to test@”%” identified by “1234”;
3. 对localhost授权(所有权限):
grant all privileges on testDB.* to test@localhost identified by ‘1234’
4. 若不想test有密码,可以再打一个命令将密码消掉。
grant select,insert,update,delete on mydb.* to test@localhost identified by ”;
5. 只创建用户不授权
insert into mysql.user(Host,User,Password) values(“localhost”,”test”,password(“1234”));
所有的用户信息都在 mysql.user这个表中
6. 撤销已经赋予给 dba用户权限的权限。
revoke all on *.* from dba@localhost;
7. 删除用户
Delete FROM user Where User=’test’ and Host=’localhost’;flush privileges;
8. 删除账户及权限
drop user 用户名@’%’;
drop user 用户名@localhost;
H. 导入.sql文件命令
①mysql> USE 数据库名;
mysql> SOURCE d:/mysql.sql;
②在DOS状态进入目录\mysql\bin,然后键入以下命令:mysql -uroot -p密码 < d:/mysql.sql
I. 备份数据库(mysqldump命令在DOS的 mysql\bin 目录下执行,命令不以分号“;”结尾)
1. 导出整个数据库: mysqldump -u用户名 -p密码 database_name > outfile_name.sql
2. 导出一个表: mysqldump -u root -p test t_user > C:\Users\Desktop\outfile_name.sql(会提示输入密码)
3. 导出一个数据库结构: mysqldump -u user_name -p -d –add-drop-table database_name > outfile_name.sql
J. 将文本数据转到数据库中:
1. 文本数据应符合的格式:字段数据之间用tab键隔开,null值用\n来代替.
1 ry 大 2010-10-10
2 uy 小 2010-12-23
假设把这两组数据存为school.txt文件,放在c盘根目录下。
2. 数据传入命令 : mysql> load data local infile “c:\school.txt” into table 表名;
K. 查询数据库中所有表名
mysql>select table_name from information_schema.tables where table_schema=’数据库名’ and table_type=’base table’;
可以通过 show create table information_schema.tables \G;来查看tables的所有字段信息,来检索你所需要的字段。
——————————————————————————–
等再熟悉了,再写吧,常练习最重要。